GENERATIVE AI in PRODUCTION
Prototype interior images generated for a home decor client. Generated from a textual embedding derived from client-supplied training material.
As with any hot technology, we get a lot of inbound requests from prospective clients looking to deploy generative AI in production. As is often the case with these situations, we’re finding that clients’ expectations of the capabilities of the system don’t align with the reality of their behavior in production.
We saw this dynamic in the past with architectural projection mapping, which photographs well from the vantage point of the projector, but can be underwhelming when seen in person, off-axis, with stereo vision, unretouched, where the projected light is fighting with ambient spill. Trying to communicate these shortcomings in advance is often met with pushback in the form of … more photos and video, which of course look great.
Today’s expectations of the capabilities of generative AI are calibrated by exposure to edited (some might say cherry-picked) samples of LLM and text-to-image outputs. I’m not trying to make a case that these systems can’t produce excellent outputs from time to time, but rather that they only do so infrequently, and that systems that expose end users to raw outputs without a curation step in the middle are likely to under-perform expectations at best, and cause a fiasco at worst.
At issue is, in part, the tendency to center the AI-generatedness of the product in its presentation, which (perversely, IMO), raises expectations in the viewer, as they have in the past likely seen some impressive AI-generated outputs.
Contributing to this is the spectacle that accompanies marketing initiatives, further raising expectations of the output quality.
As with most distributions, of course, the best stuff - the stuff that gets passed around - is under the top tail of the bell curve, and the majority - say, 85% - of the outputs, strike the viewer as anywhere from less-great-than-other-AI-stuff-they’ve-seen all the way down to objectively awful.
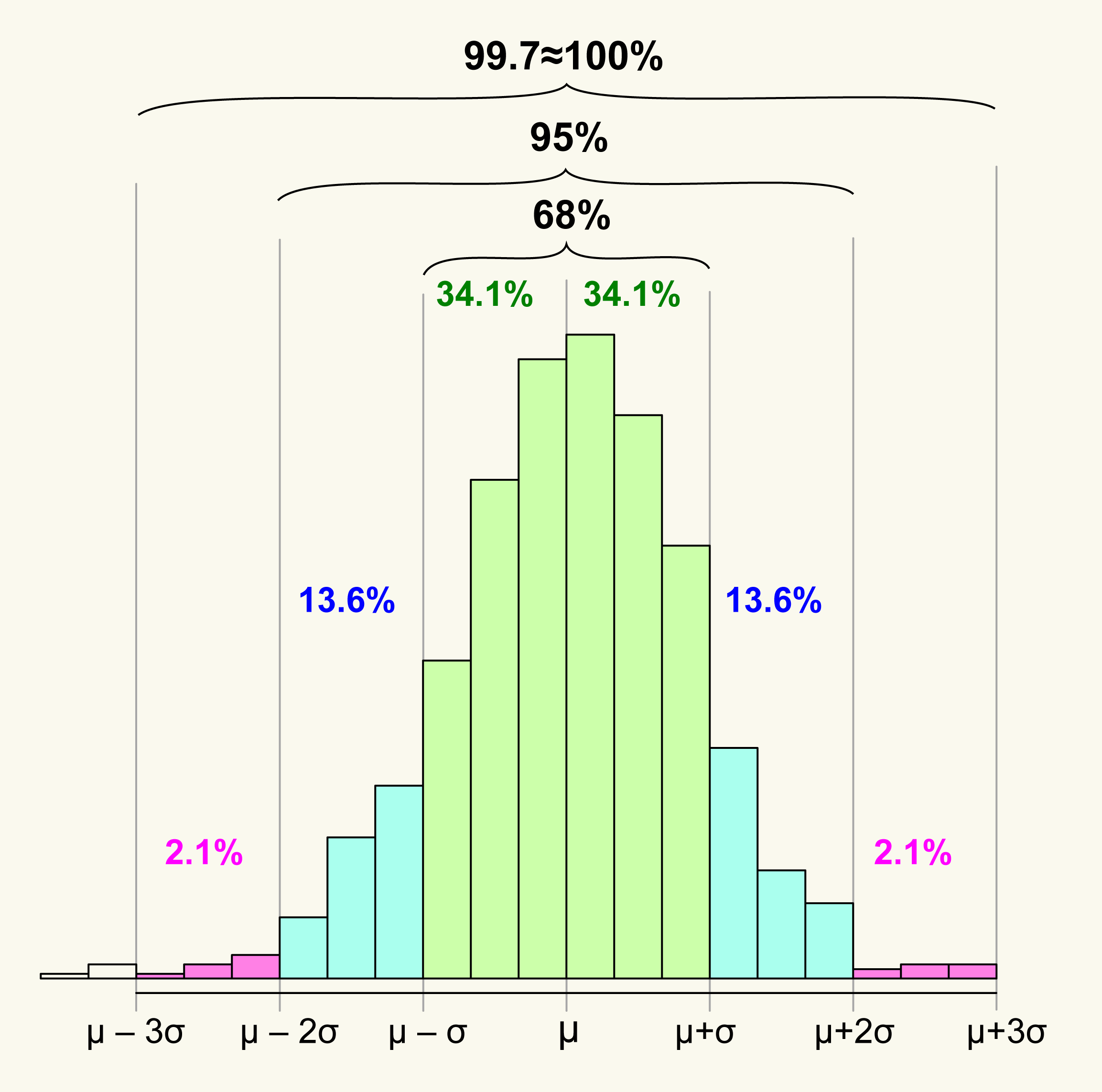 Empirical Rule by Melikamp, modified by me, CC BY-SA 4.0
Empirical Rule by Melikamp, modified by me, CC BY-SA 4.0
Especially in the world of AI-generated images, the average viewer’s level is often set by the impressive albeit all-too-recognizable and HDR’d-all-to-hell output of Midjourney. Midjourney makes aesthetically impactful images with an incredible hit rate (very few duds, munged images, deformed bodies, etc), but Midjourney is made of secret sauce and doesn’t have an API at time of this writing. That means its influence on AI image-making in real production acts exclusively to raise the bar in a way that leads to unrealistic expectations.
All of this is to say, at the moment, if you want to present the top X% of AI-generated output, you have to design your experience / system / product to accommodate an editing or curation step that removes the other (100-X)% - curation done either by the end user or by a wizard behind the curtain.
When clients push back on this idea I find myself explaining that, in service of the (often short-lived, often promotional) project they want to undertake, they’re proposing that we improve on the the state of the art products of VC-backed giants Stability and OpenAI.
This task raises a semi-rhetorical question I sometimes ask people with ambitious ideas for small projects — ‘given how much it will take to do that, it will be pretty valuable if we pull it off. Is this something you want to spin off into a startup?’
With that said, there are strategies for hiding curation and for improving the hit rate of these generative systems, and even turning the constraint of a low hit rate into a feature that contributes to an experience.
We’ve learned a lot in the last 2 years about deploying generative AI in production, and below I’ll use three recent projects to discuss how we’ve approached this issue.
HIDDEN HUMAN in the LOOP: ENTROPY

Entropy was a piece I made with Chuck Reina beginning in 2021, using then-SOTA VQGAN+CLIP and GPT-3 in a feedback loop to create what presents as a (unhinged) collectible card game.
We truthfully presented the work as the result of repeatedly prompting these two AI systems with the previous-generations’ outputs, but what we didn’t highlight was that the process involved an EXTREMELY LABOR-INTENSIVE curation step.
I personally selected among four options for every field on every card before generating the next generation, which doesn’t sound that bad until you realize that 3,000 cards * 7 fields * 4 options = 84,000 curation steps, not including the first two times I generated the first 10 generations of the project before restarting for various reasons.
To get this done, Chuck built a web-based, keyboard-driven review tool that I used for literally 50 days straight until I had carpal tunnel in both hands.
Had we not included this hidden hand, the recursive AI outputs would have quickly devolved into sophomoric jokes, pop culture references, or regurgitation of ideas from other places.
Many of you never used GPT-3 - in fact, many of you never heard of it, for good reason. It was less good than the GPTs we use today. Similarly, VQGAN+CLIP, while revolutionary, was the last of the GANs used in any major way. Diffusion models are a big step up.
If you want to read more about the process and learnings that came from this project, check out this thoughtful writeup/interview in nftnow.
CURATION as EXPERIENCE: CHEESE
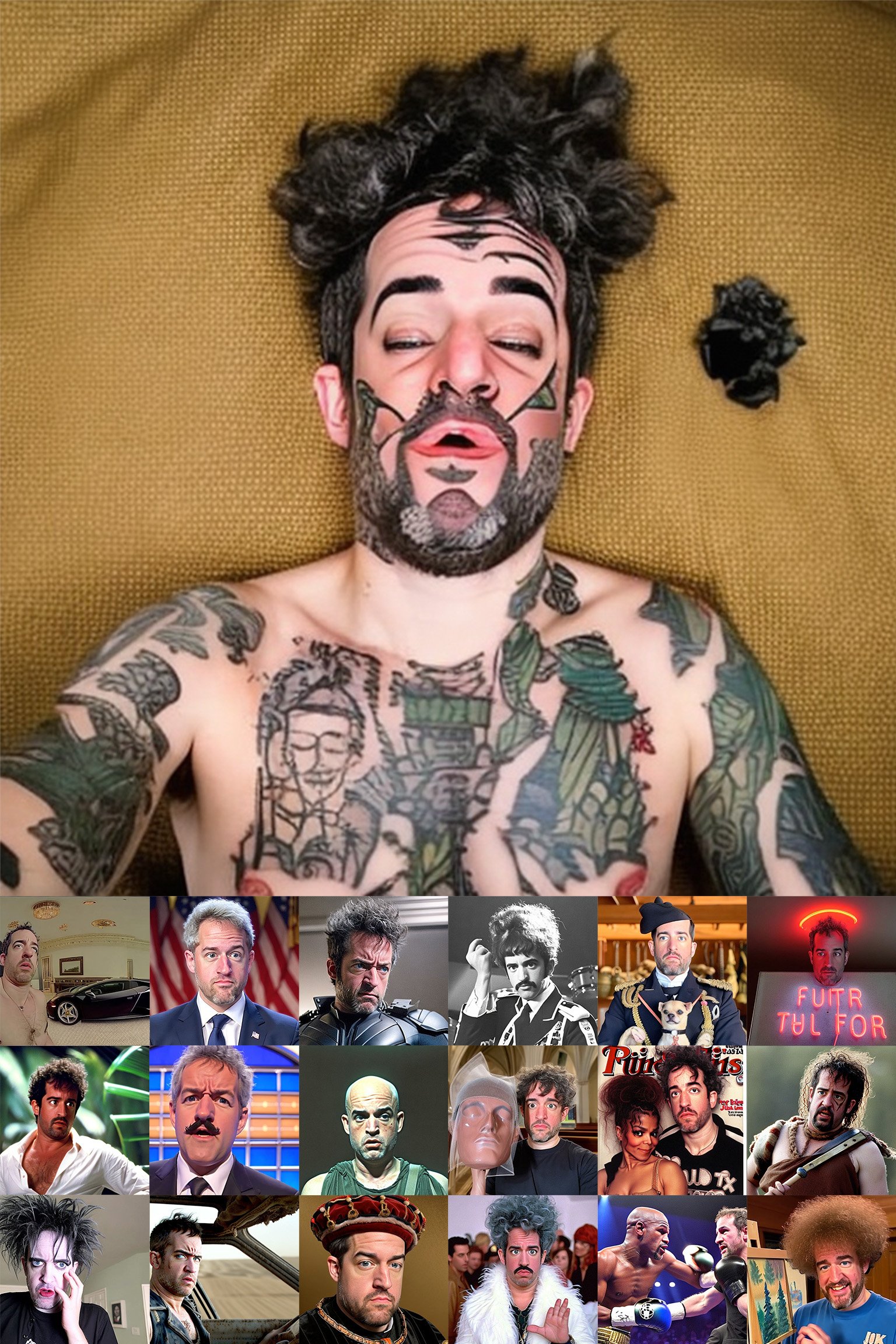 Just a small handful of the stuff on my Cheese profile page , which I encourage you to peruse.
Just a small handful of the stuff on my Cheese profile page , which I encourage you to peruse.
The first time I saw Dreambooth in action it was like being hit by a bolt of lightning. I instantly envisioned a social network that resembled Instagram but was entirely made of AI-generated images.
I immediately teamed up with a crew to make a prototype: a social network called Cheese. Users entered prompts with the keyword ‘me’ to identify themselves, posted what they liked, and hit ‘do me’ on public images of others to get a remixed version of that prompt with themselves in it.
It was, to put it mildly, addictive, sticky, hilarious, and gonzo.
What it wasn’t was magic. It produced plenty of deformed, unrecognizable, blurry, munged, off-prompt, confusing, upsetting, and disappointing images.
But Cheese was designed to be a paid service - users buy tokens, and they spend those tokens to generate - effectively to purchase - images. From interviewing users, I identified early on that one of our most important KPIs, aside from how many users we got through onboarding, or MAUs, or CAC, or ROAS, or whatever, was going to be our hit rate.
That number - what percentage of the images generated are images that a user likes - that they would post, share, download, etc. - was a major contributor to the average user’s perception of the quality of the experience, and we found that users’ initial expectations of what that number should be varied wildly, but was generally higher than we could satisfy.
We expended a ton of effort, especially for a prototype (unsurprising if you know us), in bringing that hit rate up. We ran loads of experiments on training, data preparation, inference, prompt injection, and onboarding, and internally discussed dozens of additional approaches as we saw them bubble up in papers. Some of them moved the needle, but we saw (rightly, as time has borne out) that publicly-available approaches in the space wouldn’t do much to change the balance in the coming year-plus.
With that in mind, we did what we always do: we embraced the constraints. We designed the Cheese UX with user curation at the center of the loop.
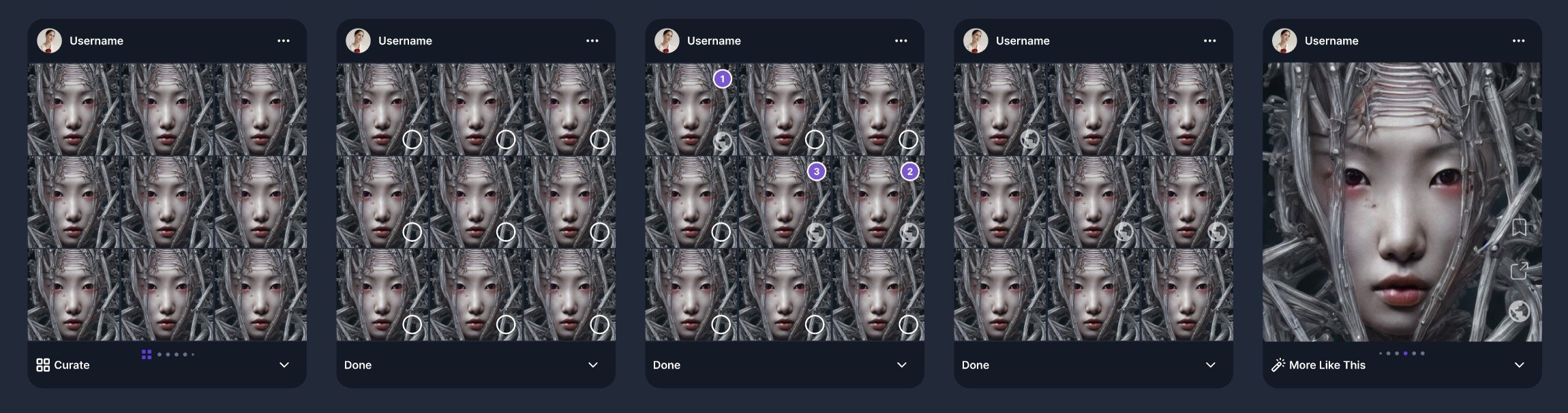
We designed a system where each prompt generated 9 variations that were only visible to the user in a private ‘camera roll’, from which they could choose to make any, or none, of the images public, only then posting them to their profile and making them visible in the public feed.
Because the users weren’t using a real camera but rather entering a prompt or hitting ‘do me’ and waiting for the results to compute, the private tab became more like a slot machine - a place our hooked users repeatedly refreshed, anticipating the dopamine hit from the variable reward of a batch of unfathomably weird, surprising, and hilarious images.
We found that this dynamic evoked how users behaved in other media, where some posted loads of their outputs, some edited heavily and posted only the very best, and some posted almost never and rather used their generations for sending privately to friends.
If we could, would we engineer a system where 100% of the images produced were ‘hits’? Absolutely. Failing that, our users were very happy with where we arrived, putting the control in their hands and making curation part of the experience.
CONSTRAIN and BATCH: INTERIORS
 Some prototype images from an ongoing project to generate interior images in a very specific style. These 9 were cherry-picked, you could say, out of a batch of 64.
Some prototype images from an ongoing project to generate interior images in a very specific style. These 9 were cherry-picked, you could say, out of a batch of 64.
We’re currently engaged an ongoing project helping a client in the decor space produce photo-realistic AI images with a very particular aesthetic. They’re attempting to use AI to reduce their costs in staging and photographing product for small-screen promotional efforts, eg in social media and in digital advertising.
Because this client has been producing photos and renderings in this style for years, the surfeit of training material meant fine-tuning of some sort was an option for capturing their look. Through some experimentation, we found a textual inversion, rather than LoRA or Dreambooth, to provide an effective and easy-to-use way to constrain generations to the style of the training material.
With that said, even a fine-tuned Stable Diffusion has issues with counting, lighting, and realism - issues exacerbated by the training material, which included loads of unconventional furnishings like amorphous couches, improbably cantilevered chairs, and side tables of indeterminate shape and material. The fine-tuned output, while instantly on-vibe, still had a low hit rate and still produced stools with 2 legs, confusing shadows, and side tables with too many surfaces.
To counteract this tendency, we found using ControlNet to be an effective way to ‘lock’ the composition of an image and iterate on its contents in a way that produces variations within a narrow range of blocking options but with different mise en scene.
That approach, combined with plain old batching - generating dozens, hundreds, or thousands of images at a go for human curation before presentation - resulted in a system that, while still batting something like .130, produces loads of high-quality, usable images at once for minimal human effort, a huge win for the client over the system they were using before, which involved unsustainable cost and supervision for the nebulous ROI of social media grist.
LASTLY
The last trick up our sleeve - compositing / collage / outpainting. De-emphasizing the importance of any given image by including it in a larger composition can make incoherent individual generations acceptable as a contribution to a surreal gestalt. Just ask Hieronymus Bosch!
We deployed this technique to great effect in the continuous-transformation inpainting process employed in Epoch Optimizer, our durational generative installation for AWS at their re:Invent conference in ‘24. Check out the case study at that link, or read our in-depth interview on the making of Epoch Optimizer with TouchDesigner makers Derivative at their site.







 The Garden of Earthly Delights, Hieronymus Bosch, c1500
The Garden of Earthly Delights, Hieronymus Bosch, c1500
Want to explore using generative AI in production? YOU KNOW WHERE TO FIND US! (here)